The stories of autonomous AI agents doing things they shouldn't do are becoming more frequent, as we could have expected.
Models are getting much better, and so is our comfort level with AI tooling. But the more comfortable we get, the more we'll see stories like "An AI Agent Just Destroyed Our Production Data".
I've written about this in "The OpenClaw turkey problem": getting comfortable because your agents haven't messed up yet and not because you have solid security primitives in place is a recipe for disaster.
So I've been thinking a lot about what those security primitives should look like (and building towards them too) and here's where I'm at.
Compromise modes
There are three core ways in which an autonomous agent [1] can get compromised:
- Prompt injection: When malicious content gets added to the model context and is able to dictate agent behavior e.g. an email from an attacker instructs the agent to send the API keys it has access to back to the attacker.
- Hallucinations: When the model behaves erratically and performs problematic actions outside of its task description e.g. deletes some data in production while trying to fix a bug.
- Unauthorized access: Or "access takeover". When an attacker manages to gain access to the agent, for instance by compromising the communication gateway e.g. they find a way to message your agent on Telegram.
Prompt injection and hallucinations are problems specific to LLM-based systems, so we'll focus on those. Unauthorized access is a common vector for attacking any system, and existing security principles apply (mostly) [2].
Assumptions
1. The lethal trifecta
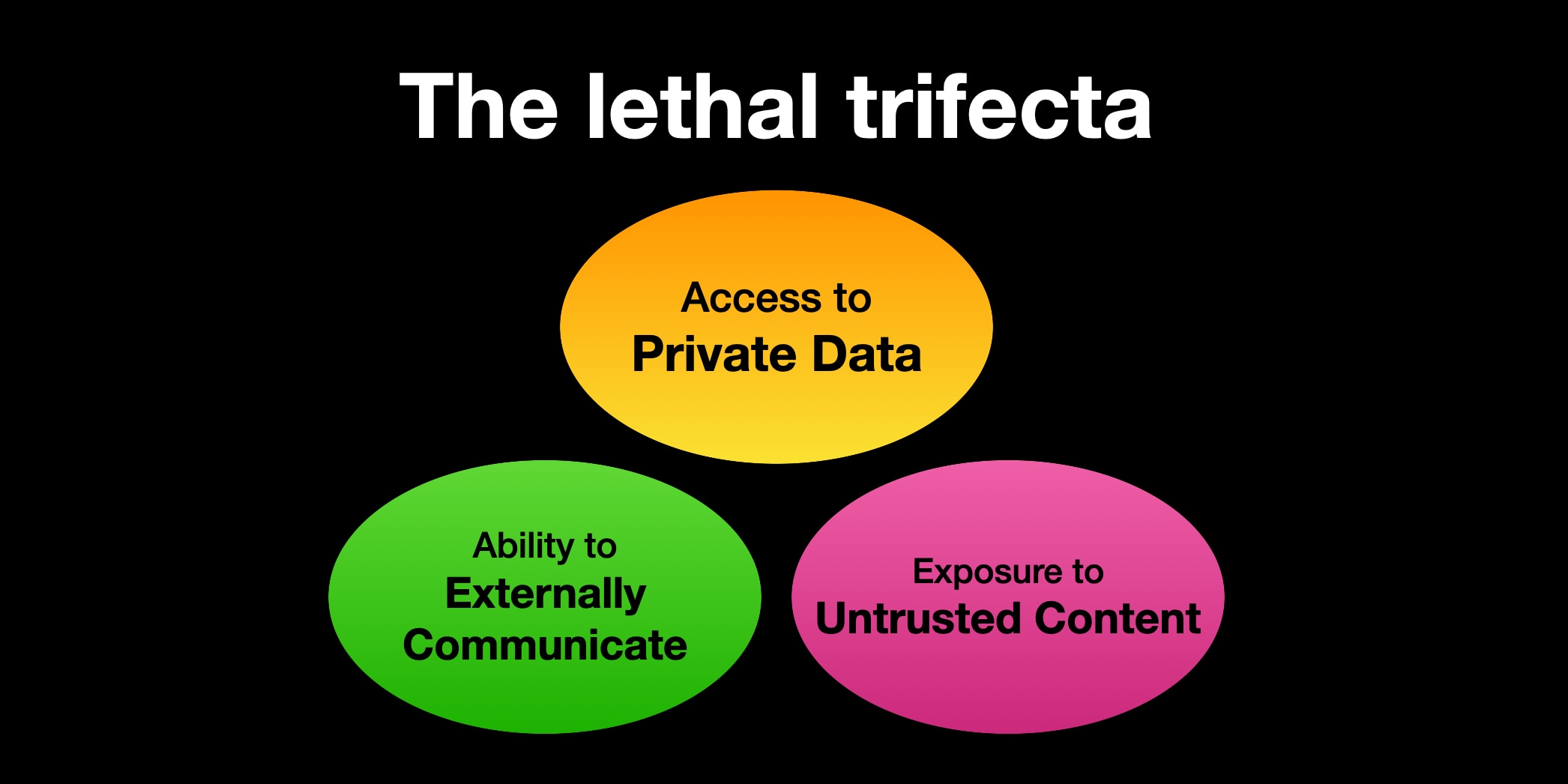
We're increasingly giving our agents more and more access, and a lot of people now run agents that have the three capabilities composing the lethal trifecta: access to private data; the ability to externally communicate; and exposure to untrusted content.
This trifecta of capabilities makes your agent prone to be severly impacted by a prompt injection attack, and most people don't even realize their agent is at such risk. Do you run Claude Code with access to your code, the ability to search the web, and the ability to make a cURL request? That's the lethal trifecta right there.
So we'll assume the agents we're talking about in this piece have all three components. Removing one of those three legs from the equation makes securing against prompt injection specifically (and hallucinations less so) a lot easier.
2. An agent with access to perform an action may at any point execute that action
Basically, if your agent has enough access to delete your prod DB, you should assume it will, and plan accordingly.
3. Any input we don't control should be considered a risk
If your agent has the ability to access any content that you don't fully control (i.e.that you wrote), you should assume it can get prompt injected.
That means searching the web, but also reading your emails. As far as complete security goes, it does also apply to reading your company's internal Slack, given that an employee's account can get compromised.
But as we'll see, a provably secure system is impossible without significantly hampering autonomous capabilities (today), so it becomes a matter of tradeoffs and risk analysis. That does not mean we shouldn't strive to build safer systems, however.
4. Malicious input may infect an agent permantently
For instance, malicious tokens from the web may not lead to data exfiltration right away, but could "poison" the system by e.g. updating internal files (think AGENTS.md) in a way that causes issues later.
5. LLM-based defenses are subject to the same issues as the agent is
LLM-based defenses can help reduce risk, but they are probabilistic at best. If the model powering the agent is subject to prompt injection, then so is the model powering the defenses.
That does not mean that these defenses are completely useless, but they are not hard boundaries.
Vulnerabilties
Having covered the compromise modes and the assumptions we're operating under, we can now move onto the vulnerabilities of these agents.
What I've tried to do here is cover the general categories of problems rather than every possible individual issue.
The list is ordered by maximum potential impact, descending.
Critical
- Performing a destructive action on a downstream service
- e.g. Making a payment, dropping a table, deleting a project on a SaaS you use
- Sensitive data exfiltration
- e.g. Your company's revenue data being sent to a malicious actor
- Credential exfiltration
- e.g. Your Anthropic API key being sent to a malicious actor
- Credential misuse
- e.g. The agent spawning a workflow that uses a ton of tokens or using a credential to perform actions that go beyond what the credential was given to the agent for
High
- Impersonation
- e.g. Acting on your behalf online, potentially affecting your reputation or causing disorder
Medium-high
- "Mine bitcoin"
- e.g. Getting infected and having its resources leveraged for a malicious third-party (without credential or sensitive data exfiltration)
Medium
- Get destroyed
- e.g. The agent does something that breaks itself in an irrecoverable way
Low
- Delete something in the machine it lives in
- e.g. The agent was keeping track of some research in the machine and it deletes it
- Brainwashing
- e.g. The agent's memory/context gets polluted and it sneakily influences your decisions (technically really high impact if it works but the best defense here is the human itself)
Mitigation
Just before we get into mitigation strategies, I think it's worth putting into perspective how hard it is to defend against these vulnerabilties, particularly due to prompt injection when the lethal trifecta is involved.
When we think of prompt injection, we often think of an agent browsing a dodgy website, and then sending a curl request with data to a dodgy URL, and put restrictions in place to limit this, such as allowlists and the like.
In reality, even setups that may seem harmless can have serious gaps. Consider the following:
- An agent that only has access to read emails and send calendar invites may send an invite to an attacker where the meeting description contains content from your private emails.
- An agent with access to GitHub issues on your open source repo via a scoped GitHub token may post your token in an issue reply, making it possible for an attacker to respond to issues on your behalf.
- An agent with access to your proprietary Node code and a proxy limiting traffic to only allow traffic from
npmand Anthropic can install a package that comes with annpmtoken and publishes your source code as a whole newnpmpackage publicly.
Avenues towards security
I've been glad to see recently that there have been more initiatives towards securing autonomous agents. I think it's clear that we need to think about this as an industry, else we risk being a turkey.
We need a more solid foundation before agents can truly take on production-level tasks safely.
Two projects that got a little traction recently are CrabTrap, built by Brex, and AgentVault, by Infisical. It's telling that companies are finding it necessary to put in guardrails before deploying agents more widely, contrary to some people's advice to ignore the risks. I'm happy to see these projects and thank them for making them open source.
CrabTrap is a man-in-the-middle (MITM) proxy that can block ougoing requests from an agent and allows you to set rules about what requests can and can't go through. It's a cool project and a very interesting implementation, but out of the critical vulnerabilities identified here, CrabTrap only aims to tackle #1 (destructive actions downstream) and #2 (sensitive data exfiltration). Credential misuse and exfiltration are out of scope, and even the vulnerabilities CrabTrap tries to tackle it does so in ways that are not entirely solid [3].
AgentVault is also a proxy, and what it does is it replaces placeholders given to your agent with real credentials at request time, in a way that your agent never sees your credentials. This addresses an issue that CrabTrap doesn't, which is credential exfiltration (#3). They mention as much in their Show HN post where it's clearly outlined that "This is the problem of credential exfiltration (not to be confused with data exfiltration)". Note that AgentVault does not help us against credential misuse (#4) because even without knowing what my API key is, the agent can still perform the actions one can take with that key, since it gets replaced in at request time.
I've also been building my own open source project, AgentPort, and it too doesn't cover the whole scope. AgentPort is a gateway for connecting agents to third-party services with granular permissioning and human-in-the-loop supervision. It let's you connect e.g. Gmail so that the agent can read your emails without approval but requires you to approve it sending an email. The same applies to Stripe, GitHub, Supabase, Cloudflare, and so on. AgentPort is a tool built primarily to tackle #1 (destructive actions downstream) and #3 (credential exfiltration). It can also help address data exfiltration (#2, provided the agent doesn't have other ways to access the web) and credential misuse (#4), but also with limitations.
Neither of these three systems completely protects us from the four critical vulnerabilties identified, but they are useful, and what's more, they show us a path towards getting there.
.png)
Devising a new system
Having seen some of what exists today, we can borrow ideas and idealize a system to secure our agents from at least the four criticial vulnerabilities identified.
This is a useful exercise to understand what an ideal system would look like, so that informed tradeoffs can be made and risks can be assessed as we tweak boundaries in order to gain functionality.
The principles of such a system would be:
- All traffic from the agent goes through a proxy.
- The agent sees no credentials. All credentials are injected by the proxy.
- The agent cannot send any data externally or perform a destructive action without approval. The proxy blocks or asks for human approval any time data is being sent out of the system. This is not as simple as blocking POST/PUT/DELETE requests, since GET requests can also exfiltrate data. Browsing the web would be a no-go, and fetching data from the web would need to have an abstraction in front.
- The proxy is able to implement rate limits. This prevents an agent from running up your bill of a service or getting your account suspended for misusing the API.
Note how in this system since we're not controlling input at all, we're ignoring vulnerabilities that damage our agent or the machine it's running on, and focusing on limiting whatever goes out. In the lethal trifecta, this is tackling the ability of the agent to communicate externally (at least without a human approving it first).
That means we're priritizing addressing vulnerabilities 1-5 (critical and high), and basically ignoring everything marked as medium-high and lower.
Even then, what we're basically doing here is limiting the agent's ability to be truly autonomous, which limits how useful it can really be.
There is some space for flexibility here, particularly around external communication. Maybe you can set the proxy to allow emails to you to go out without approval, and possibly to your team. Creating an issue on a private repo is auto-approved, but on a public repo it requires approval. Things can get hairy fast, but maybe the peace of mind is worth it.
Wrapping it up
I had two goals with this post:
- Organize my own thoughts around agent security
- Contribute to the wider discussion around securing autonomous agents
In summary, I think it's quite clear that securing agents is hard, particularly because they're subject to being compromised in ways we've never seen before, through prompt injection and hallucinations.
Progress is being made towards making LLMs more secure to both of these issues, but ultimately we're still some time away from being provably safe from these issues, given we don't have complete control nor full understanding of how LLMs behave.
At best, I believe in the short/medium-term we can make models extremely unlikely to hallucinate, as well as make finding a prompt injection attack expensive and impractical to the point that we can also consider it very unlikely.
Nevertheless, these problems are here to stay, and it's important to have productive discussions about security, even if we ultimately accept tradeoffs that sacrifice some security for more functionality. At the very least, we should know what we're getting ourselves into.
[1] You will hear me talk about "autonomous agents" throughout this post. I'm calling autonomous agents the agents that don't require you to approve the actions they take. They have access to a set of tools and can use them at their discretion. The commentary here is still extremely valid for semi-autonomous agents too, though, which would be agents that have some ability to act independently but require your approval for actions they deem riskier.
[2] One interesting concept we can bring into agents from traditional security is preventing certain destructive actions even when an attacker gains access to the system. For instance, even if I'm logged in, GitHub asks me for 2FA to delete a repo. There are ideas here that we can borrow and that limit the consequences of an attacker gaining access to your agent.
[3] CrabTrap uses hard boundaries in conjunction with LLM-as-a-judge defenses, which goes against Assumption #4 in this post. It also relies on the environment variable HTTPS_PROXY which is mostly suggestive and can be circumvented by agents.